Introduction¶
RLSolver: GPU-based Massively Parallel Environments for Large-Scale Combinatorial Optimization (CO) Problems Using Reinforcement Learning
We aim to showcase the effectiveness of GPU-based massively parallel environments for large-scale combinatorial optimization (CO) problems using reinforcement learning (RL). RL with GPU-based parallel environments can significantly improve the sampling speed and obtain high-quality solutions in a short time.
Overview¶
RLSolver has three layers:
Environments: providing massively parallel environments using GPUs.
RL agents: implementing reinforcement-learning algorithms, e.g., REINFORCE and DQN.
Problems: typical CO problems, e.g., graph Max-Cut, Knapsack, and TSP.
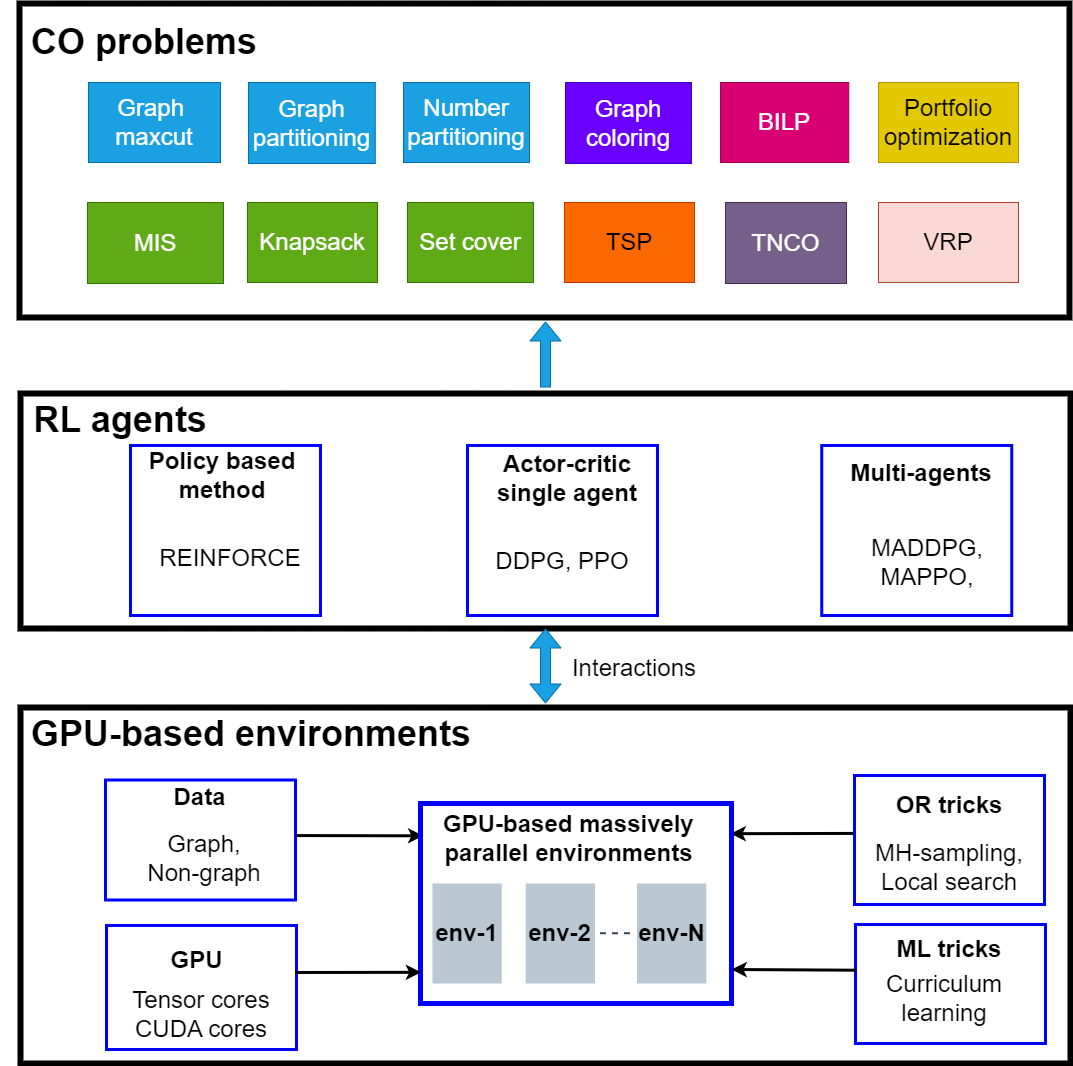
Figure 1: RLSolver overall architecture.¶
Key Technologies¶
GPU-based massively parallel environments for Markov chain Monte Carlo (MCMC) simulations on thousands of CUDA cores and tensor cores.
Distribution-wise training is orders of magnitude faster than instance-wise methods (e.g., MCPG, iSCO), since inference can be done directly on batched instances.
Why Use GPU-based Massively Parallel Environments?
The bottleneck of using RL for solving large-scale CO problems — especially in distribution-wise scenarios — is the low sampling speed, since existing solver engines (a.k.a. “gym-style” environments) are implemented on CPUs. Training the policy network is essentially estimating the gradients via a Markov chain Monte Carlo (MCMC) simulation, which requires a large number of samples from the environments.
Existing CPU-based environments have two significant disadvantages:
The number of CPU cores is typically small, generally ranging from 16 to 256, resulting in a small number of parallel environments.
The communication link between CPUs and GPUs has limited bandwidth.
GPU-based massively parallel environments overcome these disadvantages: we can build thousands of environments on the GPU, and bypass the CPU–GPU communication bottleneck; therefore the sampling speed is significantly improved.
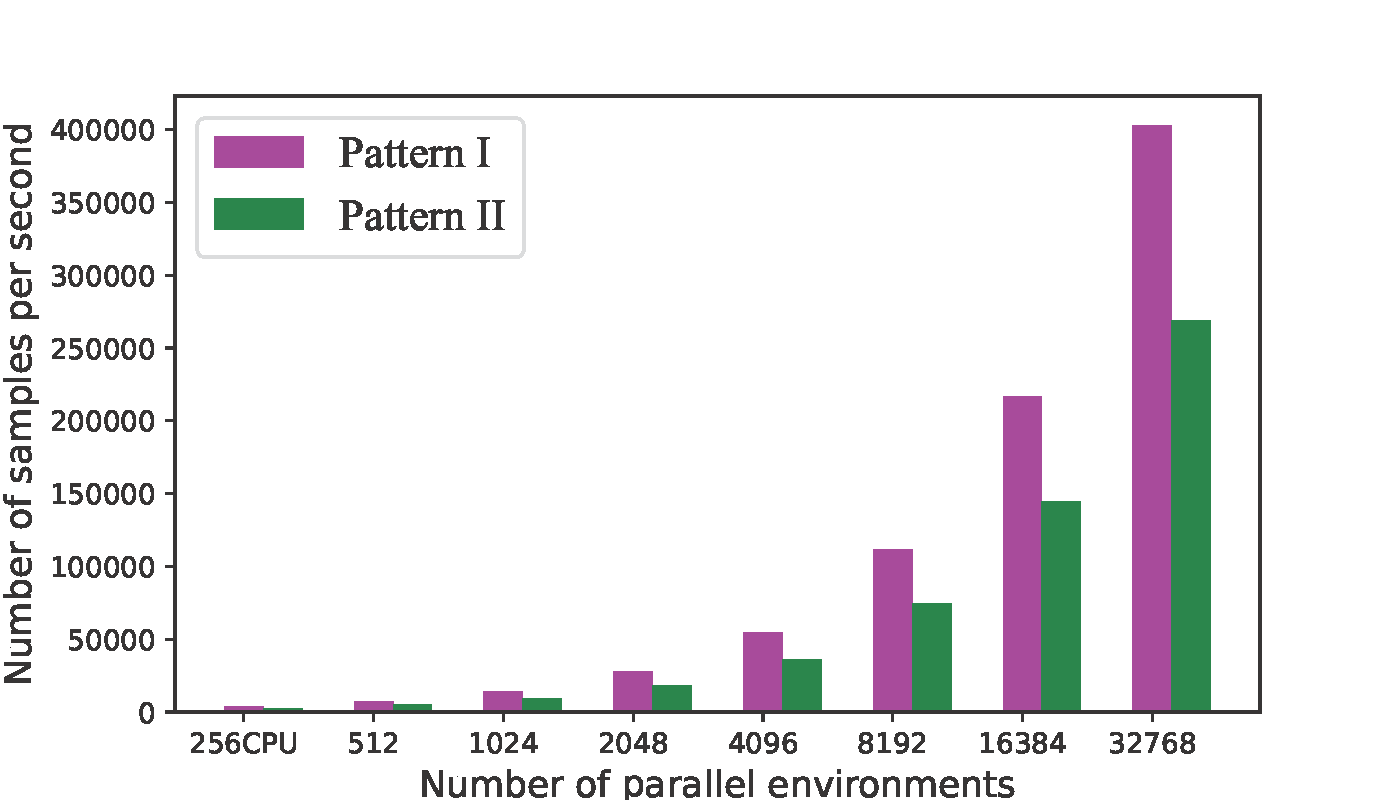
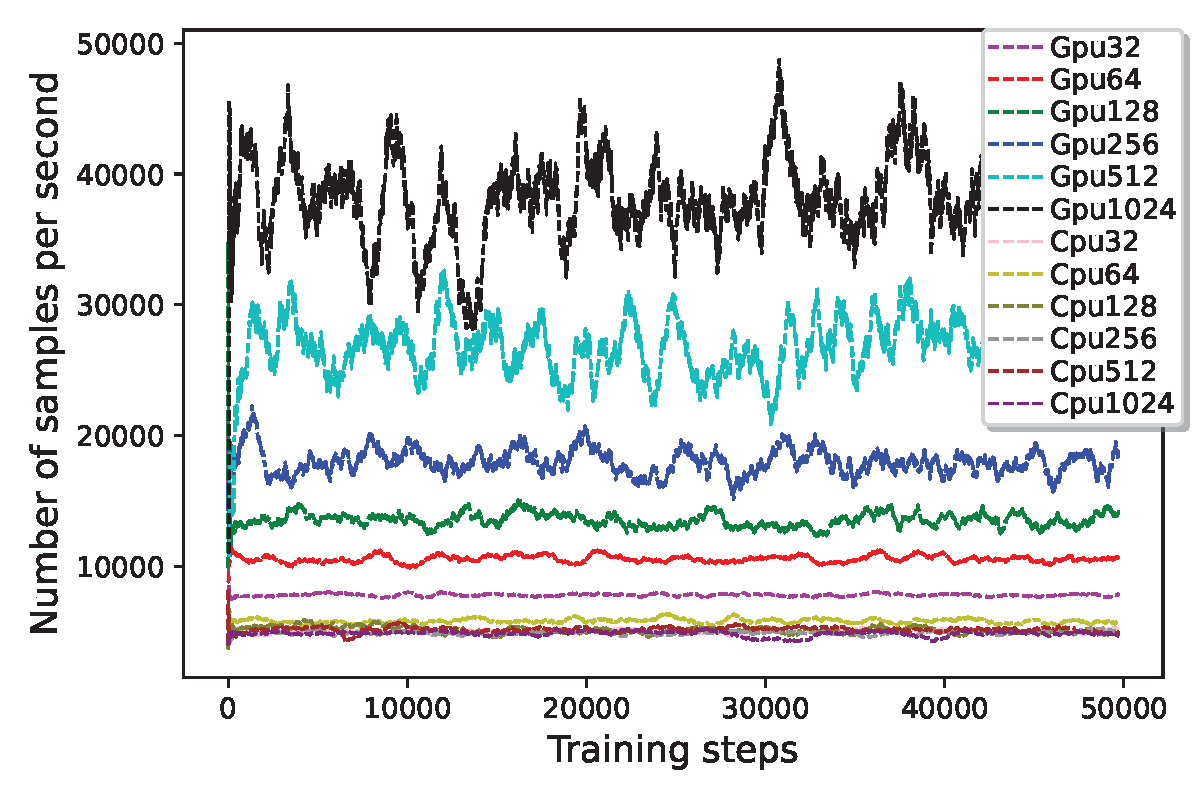
From the above figures, we used CPU and GPU based environments. We see that the sampling speed is improved by at least 2 orders by using GPU-based massively parallel environments compared with conventional CPUs.
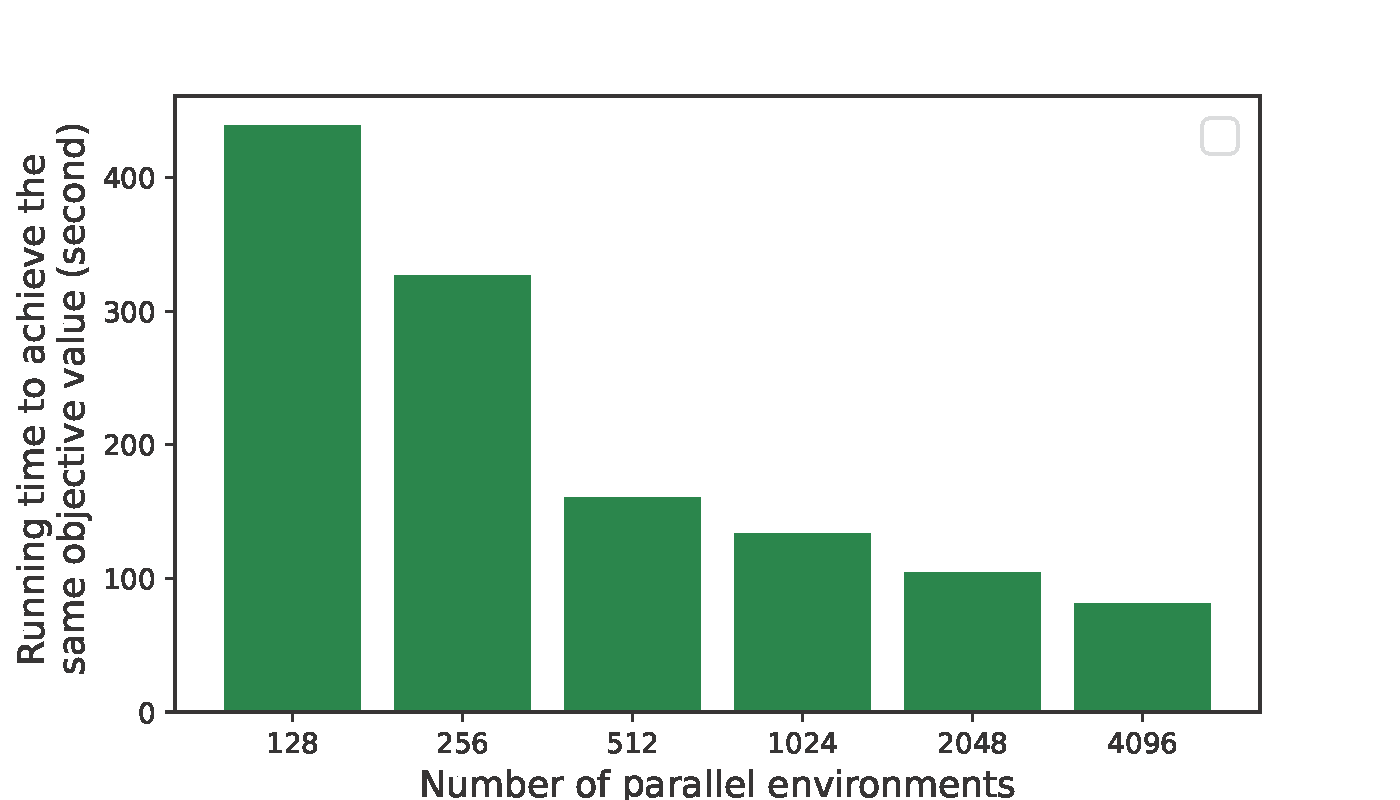
To achieve the same objective value, if we use more parallel environments, the less running time.
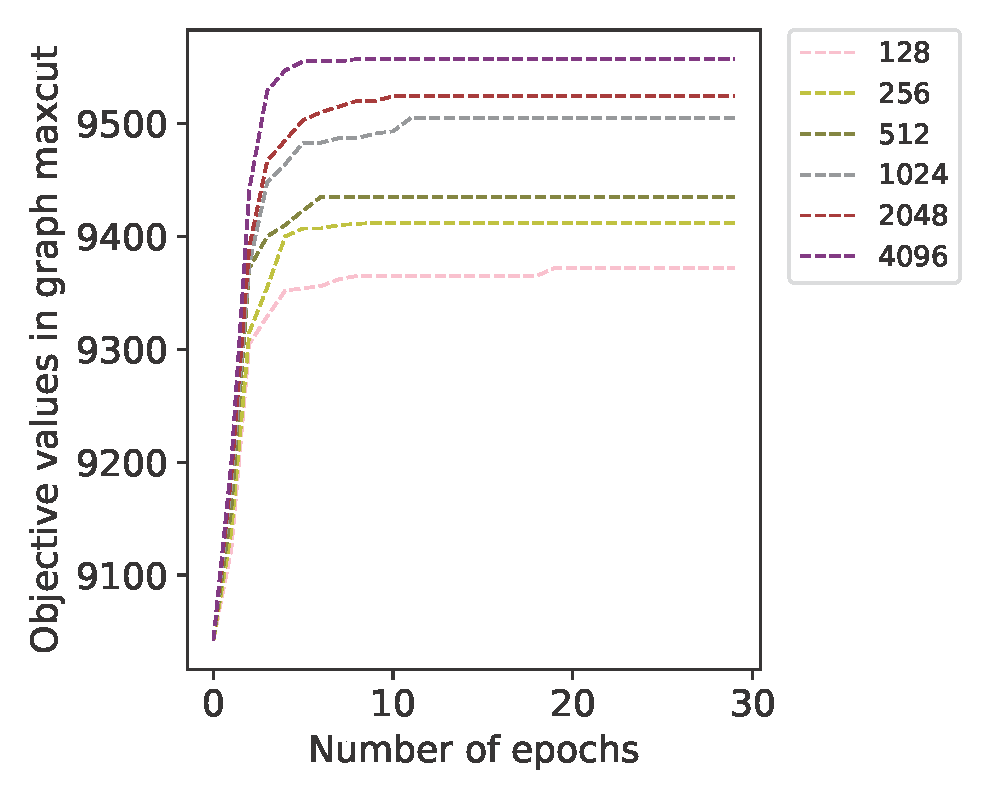
GPU-based parallel environments can significantly improve the quality of solutions during training, since RL methods require many high-quality samples from the environments for training. Take graph maxcut as an example. We select G22 in the Gset dataset. The above figure shows the objective values vs. number of epochs with different number of GPU-based parallel environments. We see that, generally, the more parallel environments, the higher objective values, and the faster convergence.
Comparison of libraries¶
Library |
RL methods |
Supported pattern |
AC algs |
Non-AC algs |
Euclidean topology |
Non-Euclidean topology |
Distribution-wise |
Instance-wise |
Problem-specific methods |
Commercial solvers |
|---|---|---|---|---|---|---|---|---|---|---|
Jumanji |
A2C |
I II |
Y |
N |
Y |
N |
Y |
N |
N |
N |
RL4CO |
A2C PPO reinforce |
I |
Y |
Only reinforce |
Y |
N |
Y |
N |
N |
N |
RLSolver (Ours) |
S2V-DQN ECO-DQN S2V-PPO MCPG dREINFORCE iSCO PI-GNN RUN-CSP etc |
I II |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Note
AC denotes actor-critic.
The differences bewteen Jumanji, RL4CO, and RLSolver are as follows.
RLSolver supports more methods than Jumanji and RL4CO, including S2V-DQN, ECO-DQN, S2V-PPO, MCPG, dREINFORCE, iSCO, PI-GNN, RUN-CSP, etc. Jumanji only supports A2C methods. RL4CO only supports three methods: A2C, PPO, and reinforce.
RLSolver supports two patterns. Jumanji also supports two patterns. But RL4CO only supports one pattern.
RLSolver supports both actor-critic (AC) and non-AC algorithms.
RLSolver can learn the graph topologies with arbitrary complex distributions, including Euclidean and Non-Euclidean topology. For example, 30% of weights of edges in the graphs are negative-infinity (i.e., the associated nodes do not connect with each other) and some weights of edges do not follow the euclidean distance topology. The methods of Jumanji and RL4CO can only learn the Euclidean topology.
RLSolver supports both distribution-wise and instance-wise scenarios. But Jumanji and RL4CO only support the distribution-wise scenario.
RLSolver supports problem-specific methods. For example, the BLS method for maxcut, the MMSE for MIMO, and the Chrisofides algorithm for TSP. Jumanji and RL4CO do not support problem-specific methods.
RLSolver supports methods using commercial solvers such as the state-of-the-art (SOTA) solver Gurobi, and we implemented the ILP and QUBO/Ising using Gurobi for CO problems. Users can develop their branch or cutting plane algorithms based on our methods. Therefore, users can compare their or our methods with the SOTA solver Gurobi. However, Jumanji and RL4CO do not spport methods using commercial solvers.